Korpus Mowy
Korpus Mowy to infrastruktura do tworzenia i archiwizacji korpusów mówionych. W ramach projektu udostępniamy korpus złożony z materiałów dźwiękowych z lat 2011-2020 i późniejszych, pochodzących głównie z serwisów internetowych. Korpus powstał w Instytucie Języka Polskiego PAN w ramach projektu „Cyfrowa infrastruktura badawcza dla humanistyki i nauk o sztuce” prowadzonego w latach 2020-2023 przez konsorcjum naukowe DARIAH-PL.
Źródła nagrań
W ramach projektu pozyskano łącznie ponad 1 000 godzin nagrań dźwiękowych z serwisów internetowych acast.com, newonce.net, soundcloud.com, spreaker.com i youtube.com.

Struktura korpusu
W skład korpusu wchodzą dwa zbiory danych. Użytkownicy mają do dyspozycji:

Spoken_full
Korpus zawiera cały materiał dźwiękowy zgromadzony w ramach projektu, a więc 1 000 godzin nagrań. Konwersja mowy na tekst została przeprowadzona automatycznie przy użyciu systemu ASR Microsoft Azure.

Spoken_selected
Korpus zrównoważony. Warstwa tekstowa przygotowana przez zespół anotatorów, pracujących w środowisku dla zasobów mulimedialnych ELAN.
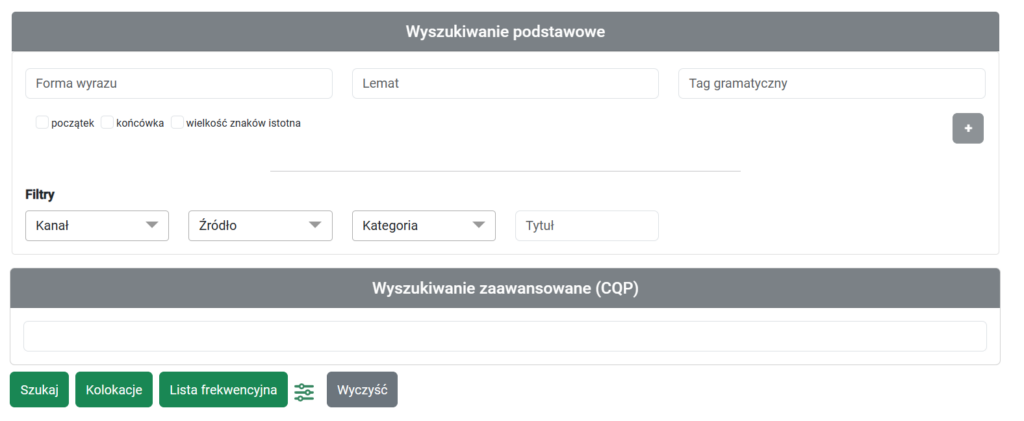
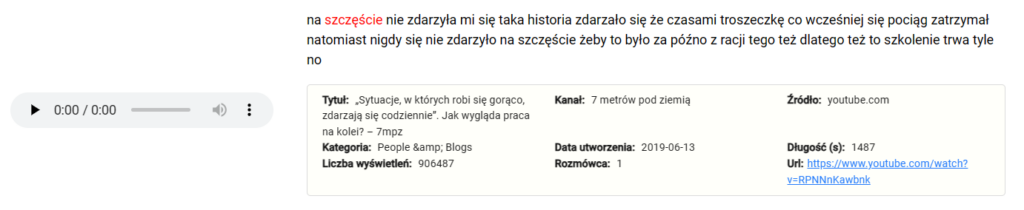
Wyszukiwarka SpoCo
Przeszukiwanie nagrań odbywa się przy użyciu wyszukiwarki SpoCo. Interfejs użytkownika daje możliwość wyszukiwania form wyrazowych (szukanie wyrazów w wersji znormalizowanej); lematów (wyszukiwanie wszystkich form danego wyrazu); tagów gramatycznych (wyszukiwanie wyrazów za pomocą ich właściwości gramatycznych). Korpus pozwala na badanie kolokacji oraz generowanie list frekwencyjnych.
Wynikami wyszukiwania są dłuższe odcinki nagrań wraz z odpowiadającymi im segmentami transkrypcji. Wyniki można eksportować do formatów CSV i XLSX.
Kanały